---
title: "Aufgaben Prüfungssprechstunde WS FS26"
title-block-banner: ./images/ffhs-farbwelt-verlauf_01.jpg
lang: de
language:
de:
author-meta-affiliation: "Hochschule"
format:
html:
include-in-header:
text: |
<script src="https://code.jquery.com/jquery-3.7.1.min.js"></script>
<style>
.title { color: white !important; }
.subtitle { color: white !important; }
.quarto-title-banner .quarto-title {
padding-left: 160px;
}
</style>
<script>
document.addEventListener('DOMContentLoaded', function () {
var banner = document.querySelector('.quarto-title-banner');
if (banner) {
banner.style.position = 'relative';
var logo = document.createElement('img');
logo.src = './images/FFHS_Logo.png';
logo.style.cssText = [
'position: absolute',
'left: 0px',
'top: 50%',
'transform: translateY(-50%)',
'height: 100px',
'width: auto',
'z-index: 10',
'filter: brightness(0) invert(1)'
].join(';');
banner.insertBefore(logo, banner.firstChild);
}
});
</script>
css: ffhs-formelsammlung.css
theme: cosmo
toc: true
toc-title: "Themen"
toc-expand: 1
toc-depth: 4
toc-location: right
code-fold: true
code-tools: true
execute:
warning: false
message: false
code-annotations: hover
editor:
markdown:
wrap: sentence
---
```{r setup, include=FALSE}
library(tidyverse)
```
## Rahmen
**Dauer:** ca. 90 Minuten
**Gesamtpunktzahl:** 60 Punkte
**Hilfsmittel:** Formelsammlung WS 2026, RStudio, Moodle
**Datensätze:** `data/webshop_checkout.csv` und `data/server_monitoring.csv`
## Datensatz A: `data/webshop_checkout.csv`
Ein mittelgrosser Schweizer Online-Shop möchte verstehen, warum ein Teil der Kundinnen und Kunden den Bestellvorgang abbricht. Dazu wurde über mehrere Wochen für jede Einkaufs-Session aufgezeichnet, mit welchem Gerät zugegriffen wurde, wie lange die Checkout-Seite zum Laden brauchte, wie viele Artikel und welcher Wert sich im Warenkorb befanden und ob die Bestellung am Ende abgeschlossen wurde. Das Marketing-Team vermutet, dass lange Ladezeiten — besonders auf mobilen Geräten — die Abschlussquote senken, und möchte diese Annahme datenbasiert prüfen.
Jede Zeile entspricht einer Session.
| Variable | Bedeutung |
|---|---|
| `session_id` | eindeutige Session-ID |
| `device` | Gerätetyp: desktop, mobile, tablet |
| `page_load_time_sec` | Ladezeit der Checkout-Seite in Sekunden |
| `cart_value_chf` | Warenkorbwert in CHF |
| `items_in_cart` | Anzahl Artikel im Warenkorb |
| `checkout_completed` | Checkout abgeschlossen: yes/no |
| `revenue_chf` | effektiver Umsatz in CHF |
| `session_duration_min` | Dauer der Session in Minuten |
| `high_load_time_prepared` | vorbereitete Variable: Ladezeit über 3 Sekunden |
## A1 – Import, Überblick und Data Wrangling
**Punkte:** 5
**Richtzeit:** 6–7 Minuten
Importieren Sie den Datensatz `webshop_checkout.csv` und bereiten Sie ihn für die Analyse vor.
1. Importieren Sie den Datensatz. (**1 Punkt**)
2. Verschaffen Sie sich mit `glimpse()` oder `summary()` einen Überblick. (**1 Punkt**)
3. Wandeln Sie `device` und `checkout_completed` in Faktoren um. (**1 Punkt**)
4. Berechnen Sie die logische Variable `high_load_time = page_load_time_sec > 3`. (**1.5 Punkte**)
5. Beschreiben Sie kurz, warum diese neue Variable praktisch nützlich sein kann. (**0.5 Punkte**)
Falls Ihnen die Berechnung von `high_load_time` nicht gelingt, verwenden Sie für spätere Aufgaben `high_load_time_prepared`.
### Musterlösung A1
```{r}
webshop <- read_csv("data/webshop_checkout.csv")
glimpse(webshop)
webshop <- webshop |>
mutate(
device = as.factor(device),
checkout_completed = as.factor(checkout_completed),
high_load_time = page_load_time_sec > 3
)
```
Die Variable `high_load_time` markiert Sessions mit einer Ladezeit über 3 Sekunden. Praktisch ist sie nützlich, weil lange Ladezeiten im Checkout ein Hinweis auf Performanceprobleme und mögliche Kaufabbrüche sein können.
| Kriterium | Punkte |
|---|---:|
| Datensatz korrekt importiert | 1 |
| Überblick mit `glimpse()` oder `summary()` erzeugt | 1 |
| kategoriale Variablen korrekt in Faktoren umgewandelt | 1 |
| `high_load_time` korrekt berechnet | 1.5 |
| praktische Bedeutung kurz erklärt | 0.5 |
---
## A2 – Verständnis zu Datenqualität, Wrangling und EDA
**Punkte:** 3
Beurteilen Sie jede Aussage als **Richtig** oder **Falsch**.
1. `device` sollte für Gruppenvergleiche sinnvollerweise als Faktor behandelt werden.
2. Die Variable `high_load_time = page_load_time_sec > 3` ist eine logische bzw. kategoriale Variable.
3. Eine extrem lange Ladezeit sollte automatisch gelöscht werden, sobald sie im Histogramm auffällt.
4. Ein Histogramm kann Hinweise auf Schiefe, Häufungen und Ausreisser einer metrischen Variable geben.
### Musterlösung A2
| Aussage | Lösung | Begründung |
|---:|---|---|
| 1 | Richtig | `device` beschreibt Gruppen und sollte für Gruppenvergleiche als Faktor behandelt werden. |
| 2 | Richtig | Die Variable nimmt nur TRUE/FALSE an. |
| 3 | Falsch | Ausreisser können fachlich relevant sein und müssen zuerst geprüft werden. |
| 4 | Richtig | Histogramme zeigen die Form einer Verteilung. |
---
## A3 – Deskriptive Statistik und EDA der Ladezeit
**Punkte:** 7
**Richtzeit:** 10–11 Minuten
Untersuchen Sie die Ladezeit `page_load_time_sec`.
1. Berechnen Sie geeignete Kennzahlen der Ladezeit nach Gerätetyp, mindestens Anzahl der Messsungen (`n`), Mittelwert, Median, Standardabweichung und IQR. (**1.5 Punkte**)
2. Erstellen Sie ein Histogramm der Ladezeit. (**1.5 Punkte**)
3. Erstellen Sie einen Boxplot der Ladezeit nach Gerätetyp. (**1.5 Punkte**)
4. Beschreiben Sie auffällige Muster, Anomalien oder Unregelmässigkeiten. Gehen Sie dabei ausdrücklich auf Histogramm und Boxplot ein. (**1.5 Punkte**)
5. Formulieren Sie eine mögliche praktische Konsequenz für den Webshop. (**1 Punkt**)
### Musterlösung A3
```{r}
webshop |>
group_by(device) |>
summarise(
n = n(),
mean_load = mean(page_load_time_sec, na.rm = TRUE),
median_load = median(page_load_time_sec, na.rm = TRUE),
sd_load = sd(page_load_time_sec, na.rm = TRUE),
iqr_load = IQR(page_load_time_sec, na.rm = TRUE),
checkout_rate = mean(checkout_completed == "yes", na.rm = TRUE)
)
```
```{r}
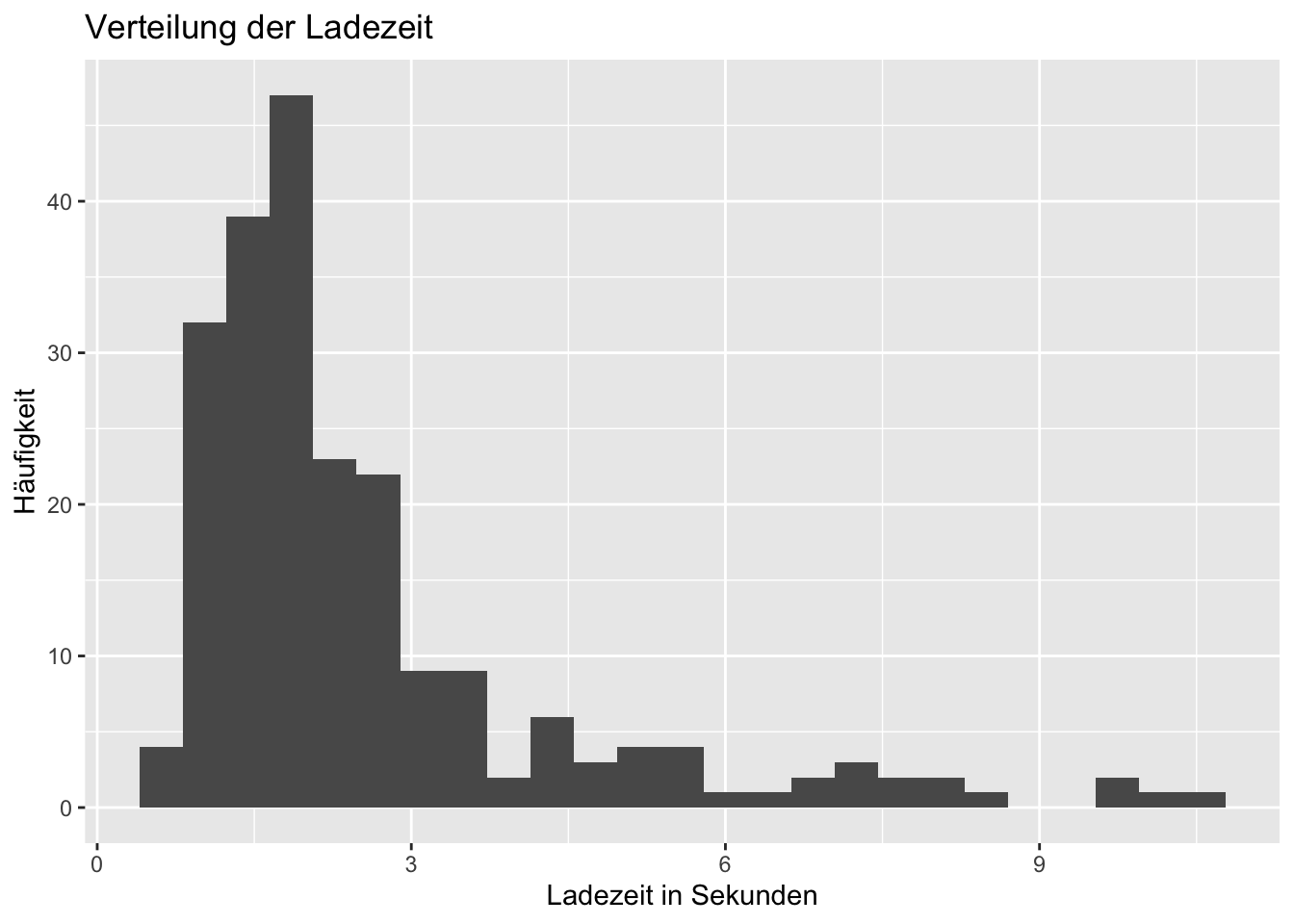
ggplot(webshop, aes(x = page_load_time_sec)) +
geom_histogram(bins = 25) +
labs(
title = "Verteilung der Ladezeit",
x = "Ladezeit in Sekunden",
y = "Häufigkeit"
)
```
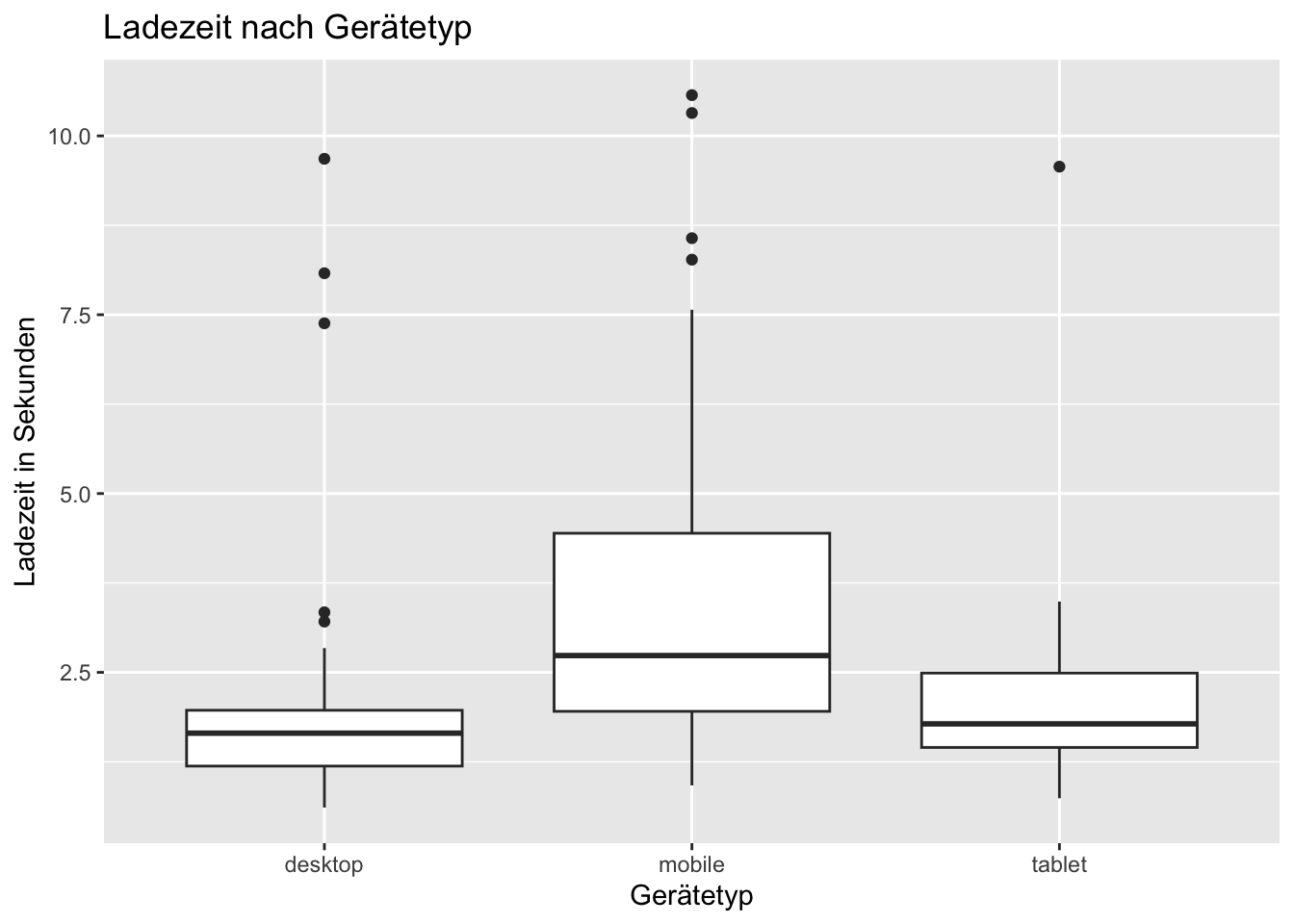
```{r}
ggplot(webshop, aes(x = device, y = page_load_time_sec)) +
geom_boxplot() +
labs(
title = "Ladezeit nach Gerätetyp",
x = "Gerätetyp",
y = "Ladezeit in Sekunden"
)
```
Die tatsächlichen Daten zeigen im Histogramm eine rechtsschiefe Verteilung der Ladezeiten. Die meisten Sessions liegen im Bereich weniger Sekunden, aber einzelne Sessions haben deutlich längere Ladezeiten bis ungefähr 10 bis 12 Sekunden. Der Boxplot zeigt, dass mobile Sessions im Mittel und Median langsamer sind als Desktop-Sessions und eine grössere Streuung aufweisen. Konkret liegt der Median bei Desktop bei ca. 1.65 Sekunden, bei Mobile bei ca. 2.74 Sekunden und bei Tablet bei ca. 1.78 Sekunden. Die Checkout-Quote ist bei mobilen Sessions mit ca. 64% tiefer als bei Desktop-Sessions mit ca. 85%.
Eine plausible praktische Konsequenz ist, die mobile Checkout-Performance gezielt zu optimieren und die extrem langen Ladezeiten technisch zu prüfen. Die Ausreisser sollten nicht automatisch gelöscht werden, weil sie gerade die problematischen Nutzererfahrungen abbilden können.
| Kriterium | Punkte |
|---|---:|
| geeignete Kennzahlen nach Gerätetyp berechnet | 1.5 |
| Histogramm erstellt | 1.5 |
| Boxplot nach Gerätetyp erstellt | 1.5 |
| Histogramm und Boxplot konkret interpretiert | 1.5 |
| praktische Konsequenz formuliert | 1 |
---
## A4 – Verständnis zu Skalenniveau und Korrelation
**Punkte:** 2
Welche Aussage ist am angemessensten?
A. `checkout_completed` ist metrisch, weil sie mit yes/no codiert ist.
B. `device` ist ordinal, weil desktop, mobile und tablet automatisch eine natürliche Reihenfolge haben.
C. `cart_value_chf` und `session_duration_min` sind metrische Variablen und können grundsätzlich mit Pearson-Korrelation untersucht werden.
D. Pearson-Korrelation ist für beliebige Variablen geeignet, solange sie in R eingelesen werden können.
### Musterlösung A4
**Richtig:** C
`cart_value_chf` und `session_duration_min` sind metrische Variablen. Für `checkout_completed` oder `device` wäre Pearson-Korrelation dagegen nicht die passende Standardmethode.
---
## A5 – Korrelation zwischen Warenkorbwert und Sessiondauer
**Punkte:** 6
**Richtzeit:** 7–8 Minuten
Untersuchen Sie den Zusammenhang zwischen `cart_value_chf` und `session_duration_min`.
1. Erstellen Sie ein Streudiagramm. (**1.5 Punkte**)
2. Berechnen Sie den Bravais-Pearson-Korrelationskoeffizienten. (**1.5 Punkte**)
3. Interpretieren Sie Richtung und Stärke des Zusammenhangs. (**1.5 Punkte**)
4. Formulieren Sie eine praktische Konsequenz und vermeiden Sie eine unzulässige Kausalaussage. (**1.5 Punkte**)
### Musterlösung A5
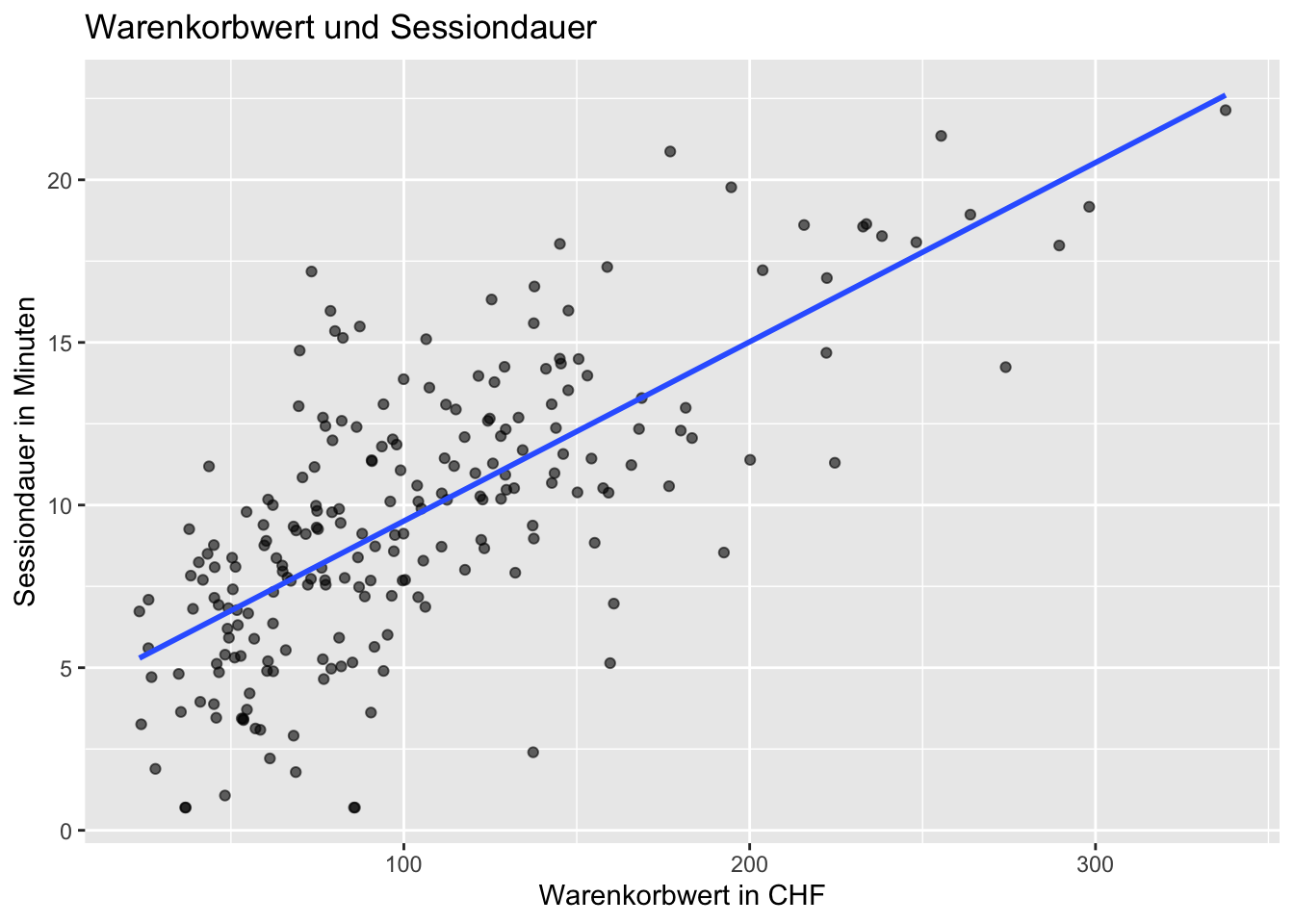
```{r}
ggplot(webshop, aes(x = cart_value_chf, y = session_duration_min)) +
geom_point(alpha = 0.6) +
geom_smooth(method = "lm", se = FALSE) +
labs(
title = "Warenkorbwert und Sessiondauer",
x = "Warenkorbwert in CHF",
y = "Sessiondauer in Minuten"
)
```
```{r}
cor(
webshop$cart_value_chf,
webshop$session_duration_min,
use = "complete.obs",
method = "pearson"
)
```
Der Pearson-Korrelationskoeffizient beträgt ca. 0.72. Das ist ein deutlich positiver Zusammenhang: Sessions mit höheren Warenkorbwerten gehen tendenziell mit längeren Sitzungsdauern einher. Im Streudiagramm ist der positive Trend sichtbar, aber die Punkte streuen weiterhin deutlich. Praktisch kann dies bedeuten, dass längere Sessions häufig komplexere oder umfangreichere Käufe enthalten. Es darf aber nicht kausal formuliert werden: Eine längere Session verursacht nicht automatisch einen höheren Warenkorbwert. Beispielsweise können auch einzele Käufe mit hohen Preisen verbunden sein. Diese Kaufentscheidung kann auch schnell erfolgen im Vergleich zu vielen niedrigpreisigen Produkten.
| Kriterium | Punkte |
|---|---:|
| Streudiagramm erstellt | 1.5 |
| Pearson-Korrelation korrekt berechnet | 1.5 |
| Richtung und Stärke korrekt interpretiert | 1.5 |
| praktische Konsequenz ohne Kausalitätsfehler formuliert | 1.5 |
---
## A6 – Konfidenzintervall für die Checkout-Quote
**Punkte:** 6
**Richtzeit:** 8–9 Minuten
i) Sie haben zwei Methoden zur Verfügung: das Wilson-Intervall (`prop.test(..., correct = FALSE)`) und das manuell berechnete Wald-Intervall. Begründen Sie, welche Methode für diese Daten geeignet ist, und prüfen Sie die zugehörige Voraussetzung. (1 Punkt)
ii) Berechnen Sie ein 95%-Konfidenzintervall (mit der Methode ihrer Wahl aus i)) für den Anteil der Sessions, bei denen der Checkout abgeschlossen wurde (`checkout_completed = "yes"`).
1. Bestimmen Sie die Anzahl abgeschlossener Checkouts und die Stichprobengrösse. (**1.5 Punkte**)
2. Berechnen Sie ein 95%-Konfidenzintervall für den Anteil abgeschlossener Checkouts. (**1.5 Punkte**)
3. Interpretieren Sie das Intervall statistisch korrekt. (**1.5 Punkte**)
4. Formulieren Sie eine mögliche praktische Konsequenz, wenn der Zielwert 80% beträgt. (**1.5 Punkte**)
### Musterlösung A6
i) Voraussetzung der Normalapproximation (ZGS-Faustregel) prüfen:
$n\hat{p} = 167 \ge 5$ und $n(1-\hat{p}) = 53 \ge 5$ — beide klar erfüllt.
Zudem ist $n = 220$ gross und $\hat{p} \approx 0.76$ weit von 0 und 1 entfernt. Damit ist das **Wald-Intervall als Näherung hier zulässig**. Als allgemein
empfohlener Standard gilt aber das **Wilson-Intervall**: Es ist robuster,
besonders bei kleinem $n$ oder $\hat{p}$ nahe 0 oder 1. In diesem Fall liefern
beide praktisch dasselbe Ergebnis, die Methodenwahl ändert die Schlussfolgerung also nicht. Antwort: Wilson bevorzugen, Wald hier vertretbar, weil die Voraussetzungen erfüllt sind.
ii)
```{r}
checkout_table <- table(webshop$checkout_completed)
checkout_table
x <- sum(webshop$checkout_completed == "yes", na.rm = TRUE)
n <- sum(!is.na(webshop$checkout_completed))
prop.test(x = x, n = n, conf.level = 0.95, correct = FALSE)
```
In den Daten wurden 167 von 220 Checkouts abgeschlossen. Der beobachtete Anteil beträgt damit ca. 75.9%. Das 95%-Konfidenzintervall liegt ungefähr zwischen 69.8% und 81.1%. Die 95%-Angabe bezieht sich auf das Verfahren, nicht auf dieses konkrete Intervall: Würde man die Stichprobenziehung sehr oft wiederholen, enthielten rund 95% der so berechneten Intervalle den wahren Anteil abgeschlossener Checkouts in der Grundgesamtheit ähnlicher Sessions. Für das hier berechnete Intervall lässt sich keine solche Wahrscheinlichkeit angeben — der wahre Anteil liegt entweder darin oder nicht. Wir könnten nur **vor** Bestimmung der Stichprobe und des KI sagen, dass wir eine 95% Wahrscheinlichkeit haben ein KI zu erhalten, welches den wahren Anteilswert enthält.
Wenn der operative Zielwert 80% beträgt, ist die Situation nicht eindeutig komfortabel: Der Punktschätzer liegt unter 80%, das Intervall reicht aber knapp über 80%. Praktisch sollte man die Checkout-Performance weiter beobachten und insbesondere mobile Sessions oder lange Ladezeiten untersuchen.
| Kriterium | Punkte |
|---|---:|
| Anzahl Erfolge und Stichprobengrösse korrekt bestimmt | 1.5 |
| 95%-Konfidenzintervall korrekt berechnet | 1.5 |
| statistische Interpretation korrekt | 1.5 |
| praktische Konsequenz anhand des Zielwerts formuliert | 1.5 |
---
## A7 – Verständnis zu Konfidenzintervallen
**Punkte:** 3
Beurteilen Sie jede Aussage als **Richtig** oder **Falsch**.
1. Ein 95%-Konfidenzintervall bedeutet, dass der wahre Parameter mit 95% Wahrscheinlichkeit in genau diesem berechneten Intervall liegt.
2. Bei gleicher Streuung wird ein Konfidenzintervall für den Mittelwert tendenziell schmaler, wenn der Stichprobenumfang steigt.
3. Ein breites Konfidenzintervall weist auf grössere Unsicherheit der Schätzung hin.
4. Ein höheres Konfidenzniveau führt bei sonst gleichen Bedingungen zu einem breiteren Konfidenzintervall.
### Musterlösung A7
| Aussage | Lösung |
|---:|---|
| 1 | Falsch |
| 2 | Richtig |
| 3 | Richtig |
| 4 | Richtig |
---
## Datensatz B: `data/server_monitoring.csv`
Ein IT-Dienstleister betreibt eine grössere Server-Flotte und überwacht sie laufend, um Ausfälle zu reduzieren und die Betriebskosten im Griff zu behalten. Für jeden Server wurden über einen Beobachtungszeitraum Kennzahlen zum Betrieb erfasst: Auslastung und Temperatur, die durchschnittliche Last (Anfragen pro Minute), die Fehlerquote, die aufgetretene Ausfallzeit, die monatlichen Betriebskosten sowie die Information, ob im Zeitraum eine Wartung durchgeführt wurde. Die Server sind nach Wichtigkeit in die Klassen standard, business und critical eingeteilt.
Das Betriebsteam möchte unter anderem wissen, wie verbreitet hohe Fehlerquoten sind, ob sich Wartung auf die Ausfallzeit auswirkt und wovon die monatlichen Kosten abhängen. Jede Zeile entspricht einem Server.
Der Datensatz enthält Monitoringdaten von Servern.
| Variable | Bedeutung |
|---|---|
| `server_id` | eindeutige Server-ID |
| `server_type` | standard, business, critical |
| `maintenance_done` | Wartung durchgeführt: yes/no |
| `cpu_usage_percent` | durchschnittliche CPU-Auslastung in Prozent |
| `temperature_c` | durchschnittliche Temperatur in Grad Celsius |
| `requests_per_min` | durchschnittliche Anfragen pro Minute |
| `error_rate` | Fehlerquote |
| `downtime_min` | Ausfallzeit in Minuten |
| `monthly_cost_chf` | monatliche Betriebskosten in CHF |
| `high_error_prepared` | vorbereitete Variable: Fehlerquote über 5% |
## B1 – Import, Wrangling und Anteil hoher Fehlerrate
**Punkte:** 4
**Richtzeit:** 6–7 Minuten
Importieren Sie den Datensatz `server_monitoring.csv` und bereiten Sie ihn für die Analyse vor.
1. Importieren Sie den Datensatz und verschaffen Sie sich einen kurzen Überblick. (**0.75 Punkte**)
2. Wandeln Sie `server_type` und `maintenance_done` in Faktoren um. (**0.75 Punkte**)
3. Erzeugen Sie die logische Variable `high_error = error_rate > 0.05`. (**1 Punkt**)
4. Berechnen Sie Anzahl und Anteil der Server mit hoher Fehlerrate. (**1 Punkt**)
5. Interpretieren Sie kurz, wofür die Variable `high_error` praktisch nützlich ist. (**0.5 Punkte**)
Falls Ihnen die Berechnung von `high_error` nicht gelingt, verwenden Sie `high_error_prepared`.
### Musterlösung B1
```{r}
server <- read_csv("data/server_monitoring.csv")
glimpse(server)
server <- server |>
mutate(
server_type = as.factor(server_type),
maintenance_done = as.factor(maintenance_done),
high_error = error_rate > 0.05
)
server |>
summarise(
n = n(),
n_high_error = sum(high_error, na.rm = TRUE),
share_high_error = mean(high_error, na.rm = TRUE)
)
```
In den Daten haben 33 von 180 Servern eine Fehlerquote über 5%. Der Anteil beträgt ca. 18.3%. Die Variable `high_error` ist praktisch nützlich, weil sie Server mit potenziell kritischer Stabilität schnell identifiziert.
| Kriterium | Punkte |
|---|---:|
| Datensatz korrekt importiert und Überblick erzeugt | 0.75 |
| Faktoren korrekt erzeugt | 0.75 |
| `high_error` korrekt berechnet oder Ersatzvariable verwendet | 1 |
| Anzahl und Anteil korrekt berechnet | 1 |
| praktische Bedeutung kurz interpretiert | 0.5 |
---
## B2 – Verständnis zu Verteilungen und Binomialmodell
**Punkte:** 2
Beurteilen Sie jede Aussage als **Richtig** oder **Falsch**.
1. Die Anzahl Server mit hoher Fehlerrate in einer festen Stichprobe kann unter geeigneten Annahmen mit einer Binomialverteilung modelliert werden.
2. Eine stetige Zufallsvariable nimmt an einem exakten Einzelwert typischerweise eine positive Wahrscheinlichkeit an.
3. Für eine Binomialverteilung wird im Modell eine fixe Erfolgswahrscheinlichkeit $p$ angenommen.
4. Die Normalverteilung ist immer geeignet, sobald ein Histogramm ungefähr symmetrisch aussieht.
### Musterlösung B2
| Aussage | Lösung | Begründung |
|---:|---|---|
| 1 | Richtig | Die Anzahl Erfolge in einer festen Anzahl Beobachtungen kann binomial modelliert werden, wenn die Annahmen passen. |
| 2 | Falsch | Bei stetigen Verteilungen ist die Wahrscheinlichkeit für einen exakten Einzelwert typischerweise 0. |
| 3 | Richtig | Die konstante Erfolgswahrscheinlichkeit ist Teil des Binomialmodells. |
| 4 | Falsch | Zusätzlich müssen Kontext, Skalenniveau, Ausreisser und Modellzweck geprüft werden. |
---
## B3 – Binomialmodell im Serverkontext
**Punkte:** 4
**Richtzeit:** 5–6 Minuten
Nehmen Sie an, der beobachtete Anteil von Servern mit hoher Fehlerrate aus B1 sei eine Schätzung für die Wahrscheinlichkeit, dass ein zufällig ausgewählter Server eine hohe Fehlerrate aufweist.
1. Begründen Sie kurz, warum die Anzahl Server mit hoher Fehlerrate in einer festen Stichprobe grundsätzlich mit einer Binomialverteilung modelliert werden kann. (**1 Punkt**)
2. Nennen Sie zwei Voraussetzungen, die dafür erfüllt sein sollten. (**1 Punkt, je 0.5 Punkte**)
3. Berechnen Sie mit dem beobachteten Anteil als Schätzung für $p$ die Wahrscheinlichkeit, dass unter 20 neuen Servern mindestens 5 eine hohe Fehlerrate aufweisen. (**1.5 Punkte**)
4. Formulieren Sie eine praktische Bedeutung eines hohen Anteils von Servern mit hoher Fehlerrate. (**0.5 Punkte**)
### Musterlösung B3
```{r}
p_hat <- mean(server$high_error, na.rm = TRUE)
p_hat
1 - pbinom(4, size = 20, prob = p_hat)
```
Die Anzahl Server mit hoher Fehlerrate kann als Anzahl von Erfolgen in einer festen Anzahl von Beobachtungen betrachtet werden. Ein Erfolg ist hier: `high_error = TRUE`. Voraussetzungen sind unter anderem eine feste Anzahl Beobachtungen, näherungsweise unabhängige Server und eine im Modell konstante Erfolgswahrscheinlichkeit $p$.
Der beobachtete Anteil beträgt ca. 18.3%. Mit diesem Wert als Schätzung für $p$ beträgt die Wahrscheinlichkeit, dass unter 20 neuen Servern mindestens 5 eine hohe Fehlerrate aufweisen, ca. 29.9%. Praktisch bedeutet ein hoher Anteil, dass Stabilitätsprobleme nicht nur Einzelfälle sind und priorisiert untersucht werden sollten.
| Kriterium | Punkte |
|---|---:|
| Binomialidee korrekt erklärt | 1 |
| zwei Voraussetzungen korrekt genannt | 1 |
| Wahrscheinlichkeit mit `pbinom()` oder äquivalenter Rechnung korrekt berechnet | 1.5 |
| praktische Bedeutung formuliert | 0.5 |
---
## B4 – Hypothesentest: Wartung und Downtime
**Punkte:** 6
**Richtzeit:** 9–10 Minuten
Untersuchen Sie, ob sich die mittlere Ausfallzeit `downtime_min` zwischen Servern mit und ohne Wartung unterscheidet.
1. Formulieren Sie geeignete Null- und Alternativhypothese. (**1 Punkt**)
2. Berechnen Sie deskriptive Kennzahlen der Ausfallzeit nach Wartungsstatus. (**1 Punkt**)
3. Führen Sie einen geeigneten Test in R durch. (**1.5 Punkte**)
4. Interpretieren Sie den p-Wert und den Testentscheid bei $\alpha = 0.05$. (**1.5 Punkte**)
5. Formulieren Sie eine praktische Konsequenz und vermeiden Sie eine unzulässige Kausalaussage. (**1 Punkt**)
### Musterlösung B4
$H_0: \mu_{\text{Wartung ja}} = \mu_{\text{Wartung nein}}$
$H_1: \mu_{\text{Wartung ja}} \neq \mu_{\text{Wartung nein}}$
```{r}
server |>
group_by(maintenance_done) |>
summarise(
n = n(),
mean_downtime = mean(downtime_min, na.rm = TRUE),
median_downtime = median(downtime_min, na.rm = TRUE),
sd_downtime = sd(downtime_min, na.rm = TRUE),
mean_error_rate = mean(error_rate, na.rm = TRUE)
)
t.test(downtime_min ~ maintenance_done, data = server)
```
Die mittlere Ausfallzeit beträgt bei Servern ohne Wartung ca. 34.4 Minuten und bei Servern mit Wartung ca. 21.0 Minuten. Der p-Wert des Welch-Tests ist sehr klein, ca. $2.2 \cdot 10^{-16}$. Bei $\alpha = 0.05$ wird die Nullhypothese verworfen. Die Daten liefern also starke Hinweise auf einen Unterschied der mittleren Ausfallzeit zwischen den Gruppen.
Praktisch spricht dies dafür, Wartungsprozesse ernst zu nehmen und Server ohne Wartung genauer zu prüfen. Kausal darf man das Ergebnis aber nicht überinterpretieren: Es handelt sich um Beobachtungsdaten; Servertyp, Kritikalität oder Auslastung könnten ebenfalls eine Rolle spielen.
| Kriterium | Punkte |
|---|---:|
| Null- und Alternativhypothese korrekt formuliert | 1 |
| deskriptive Kennzahlen nach Gruppe berechnet | 1 |
| geeigneter Test in R durchgeführt | 1.5 |
| p-Wert und Entscheid korrekt interpretiert | 1.5 |
| praktische Konsequenz ohne Kausalitätsfehler formuliert | 1 |
---
## B5 – Verständnis zu Modellannahmen bei Einfachregression
**Punkte:** 2
Ein einfaches lineares Regressionsmodell weist ein hohes $R^2$ auf. Im Residuenplot ist jedoch eine deutliche Trichterform sichtbar. Welche Aussage ist am angemessensten?
A. Das Modell ist automatisch gut, weil ein hohes $R^2$ alle Modellprobleme ausschliesst.
B. Das Modell sollte kritisch geprüft werden, weil die Trichterform auf ungleichmässige Residuenstreuung hinweisen kann.
C. Der Residuenplot ist irrelevant, wenn die Regressionsgerade steigend ist.
D. Eine Trichterform beweist, dass alle Daten falsch erhoben wurden.
### Musterlösung B5
**Richtig:** B
Ein hohes $R^2$ bedeutet nicht automatisch, dass alle Modellannahmen erfüllt sind. Eine Trichterform kann auf Heteroskedastizität bzw. ungleichmässige Streuung der Residuen hinweisen.
---
## B6 – Einfache lineare Regression: Serverkosten erklären
**Punkte:** 7
**Richtzeit:** 10–12 Minuten
Modellieren Sie die monatlichen Serverkosten `monthly_cost_chf` mit der erklärenden Variable `requests_per_min`.
1. Erstellen Sie ein Streudiagramm mit Regressionsgerade. (**1 Punkt**)
2. Schätzen Sie ein einfaches lineares Regressionsmodell in R. (**1.5 Punkte**)
3. Interpretieren Sie den Regressionskoeffizienten von `requests_per_min` inhaltlich. (**1.5 Punkte**)
4. Interpretieren Sie die Modellgüte anhand von $R^2$. (**1 Punkt**)
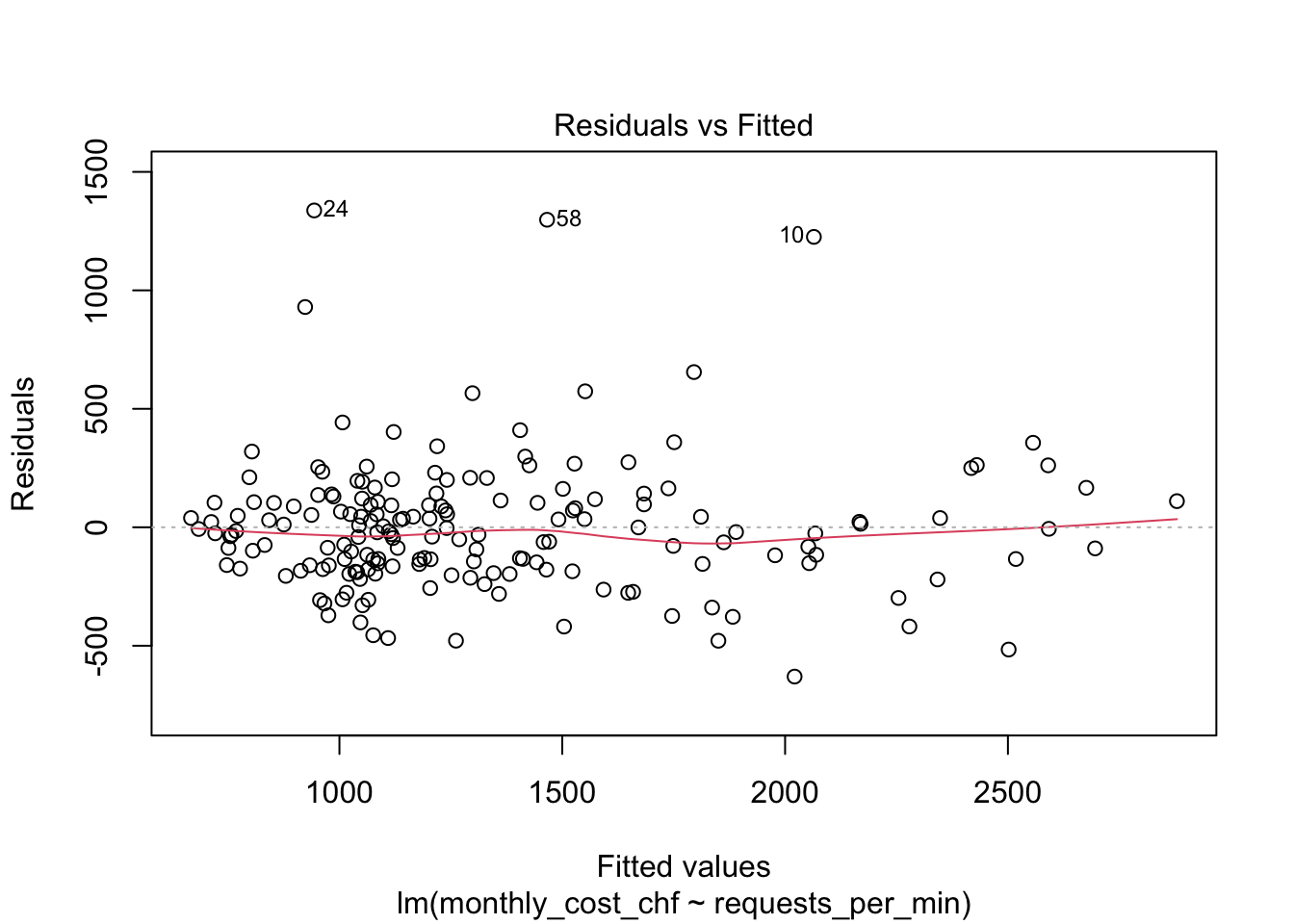
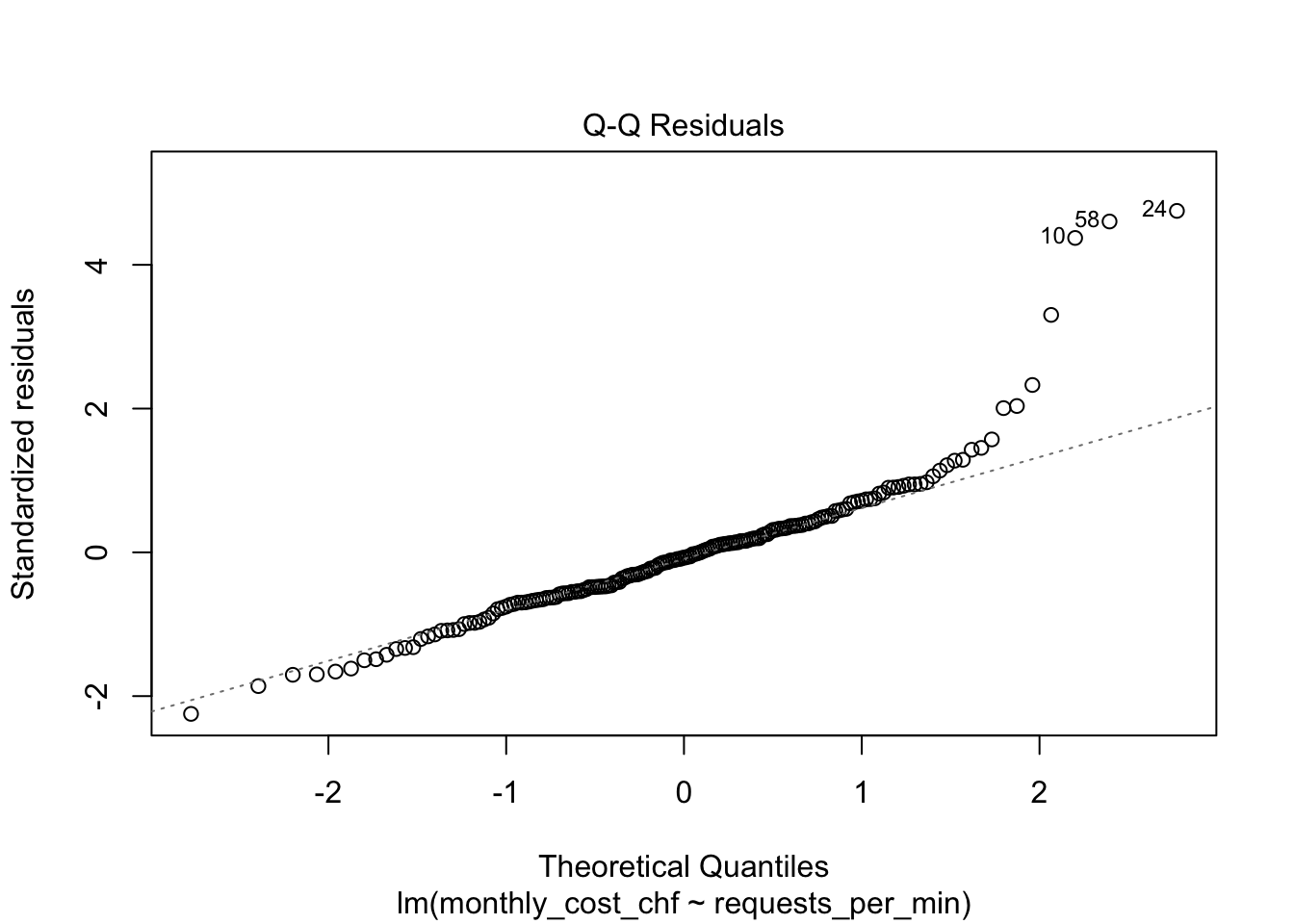
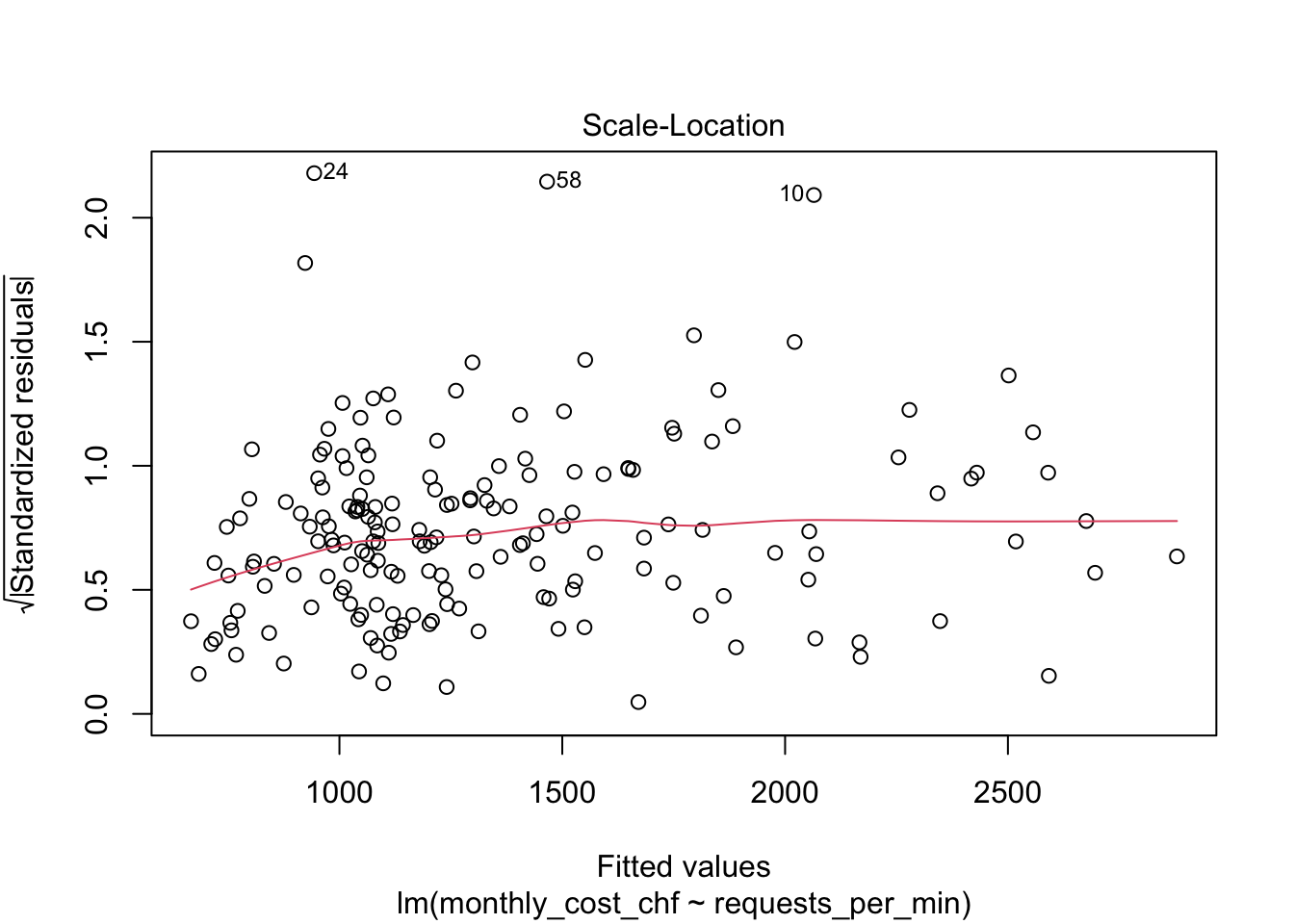
5. Prüfen Sie die Modellvoraussetzungen anhand geeigneter Diagnoseplots, insbesondere Residuenplot und QQ-Plot. (**1 Punkt**)
6. Beschreiben Sie auffällige Muster, Anomalien oder Grenzen des Modells. (**1 Punkt**)
### Musterlösung B6
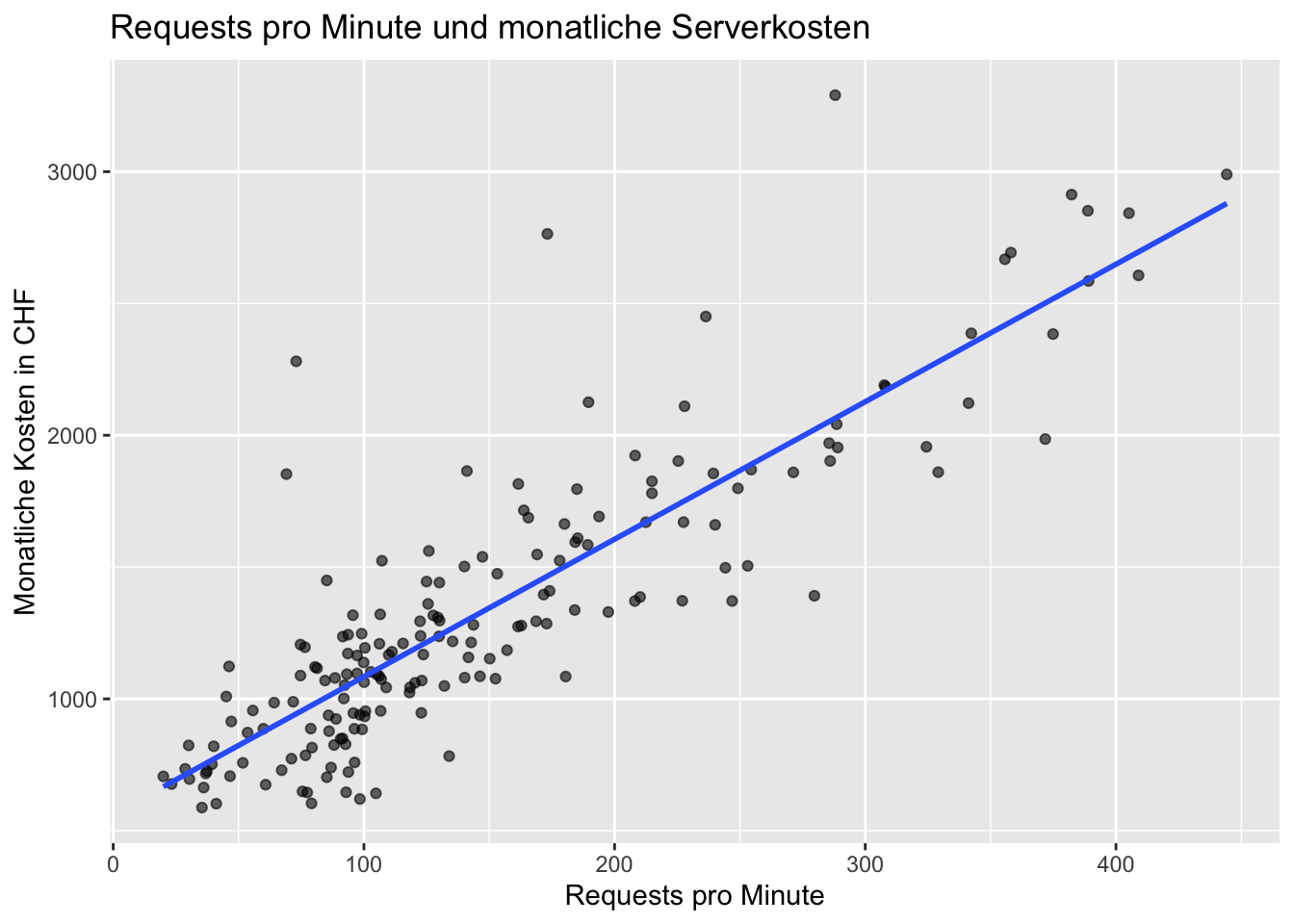
```{r}
ggplot(server, aes(x = requests_per_min, y = monthly_cost_chf)) +
geom_point(alpha = 0.6) +
geom_smooth(method = "lm", se = FALSE) +
labs(
title = "Requests pro Minute und monatliche Serverkosten",
x = "Requests pro Minute",
y = "Monatliche Kosten in CHF"
)
```
```{r}
model_cost <- lm(monthly_cost_chf ~ requests_per_min, data = server)
summary(model_cost)
```
```{r}
plot(model_cost)
```
Das einfache Regressionsmodell hat ungefähr die Form:
$\widehat{monthly\_cost\_chf} \approx 563 + 5.22 \cdot requests\_per\_min$.
Der Koeffizient von `requests_per_min` bedeutet: Wenn die durchschnittliche Anzahl Requests pro Minute um 1 steigt, steigen die erwarteten monatlichen Kosten im Modell um ungefähr 5.22 CHF. Da es sich um eine Einfachregression handelt, werden keine weiteren Variablen kontrolliert.
Das $R^2$ liegt bei ca. 0.74. Das Modell erklärt also ungefähr 74% der Variation der monatlichen Kosten. Das ist eine relativ hohe Modellgüte für einen einzelnen Prädiktor. Im Streudiagramm ist ein klar positiver linearer Trend sichtbar. Die Diagnoseplots sollten trotzdem geprüft werden: Es gibt einzelne Server mit ungewöhnlich hohen Kosten und bei höheren vorhergesagten Werten kann die Streuung zunehmen. Das Modell ist daher für eine grobe Kostenabschätzung nützlich, ersetzt aber keine detaillierte Kostenanalyse nach Servertyp, Auslastung oder Spezialfällen.
| Kriterium | Punkte |
|---|---:|
| Streudiagramm mit Regressionsgerade erstellt | 1 |
| einfaches Regressionsmodell korrekt geschätzt | 1.5 |
| Steigungskoeffizient korrekt interpretiert | 1.5 |
| $R^2$ korrekt eingeordnet | 1 |
| Diagnoseplots erzeugt und Modellvoraussetzungen geprüft | 1 |
| Auffälligkeiten oder Grenzen des Modells beschrieben | 1 |
---
## B7 – Kurze Praxisbeurteilung
**Punkte:** 3
**Richtzeit:** 4–5 Minuten
Fassen Sie auf Basis Ihrer Analysen aus Datensatz B kurz zusammen, welche zwei Variablen aus Sicht eines Server-Betriebsteams besonders wichtig wären.
1. Nennen Sie zwei sinnvolle Variablen. (**1 Punkt**)
2. Begründen Sie mindestens eine Variable statistisch. (**1 Punkt**)
3. Begründen Sie mindestens eine Variable praktisch. (**1 Punkt**)
### Musterlösung B7
Sinnvolle Variablen wären z.B. `error_rate`, `high_error`, `downtime_min`, `requests_per_min`, `monthly_cost_chf` oder `cpu_usage_percent`. Eine gute Antwort verbindet statistische und praktische Bedeutung. Beispielsweise ist `downtime_min` relevant, weil sie sich in den Daten deutlich zwischen Servern mit und ohne Wartung unterscheidet. Praktisch ist sie wichtig, weil Ausfallzeit direkt die Verfügbarkeit und Servicequalität betrifft. `monthly_cost_chf` ist ebenfalls wichtig, weil die Regression zeigt, dass die Kosten stark mit der Last durch Requests zusammenhängen.
| Kriterium | Punkte |
|---|---:|
| zwei sinnvolle Kennzahlen genannt | 1 |
| statistische Begründung zu mindestens einer Kennzahl | 1 |
| praktische Begründung zu mindestens einer Kennzahl | 1 |